Hypothesise
An AI-Powered Operating System for Experimentation





A lot of product work lives in the gap between “I think there's a problem here” and “here's a test we can actually ship.” You notice something in the data, you have a hunch, and then it takes hours to turn that into something a developer can act on. Hypothesise is a tool I built to close that gap.
What it does
You feed it the inputs a product or growth team already has — a page URL, analytics data, heuristic notes, observations from session recordings — and it produces structured, developer-ready test briefs in minutes.
The workflow is: create an audit for a page, pull in metrics, add context through annotated screenshots and session notes, generate hypotheses. Claude looks at the full picture and returns ranked, evidence-backed test ideas. Approving one spits out a complete brief — control and variant descriptions, success metrics, dev notes, QA checklist — in a single click.
How it's built
Backend is FastAPI with all Claude API calls routed through a versioned prompt registry. Every prompt version is immutable once released and every generation is logged — which matters when the output is something people are actually shipping from. Frontend is Next.js with Tailwind, backed by Supabase for auth, database, and file storage. Screenshots are captured server-side via Playwright, and an annotation layer lets you drop pins on friction points before generation so the model has richer context to work from.
The prompt system is on its sixth iteration and is built on top of a few key frameworks — UX best practices, common interaction patterns, industry-specific conversion drivers, and design system guidelines. Version 6 added routing across 12 page types and an industry context block covering 18 verticals, so the model knows whether it's looking at a consumer checkout or a SaaS onboarding screen and can reason from the right set of assumptions.
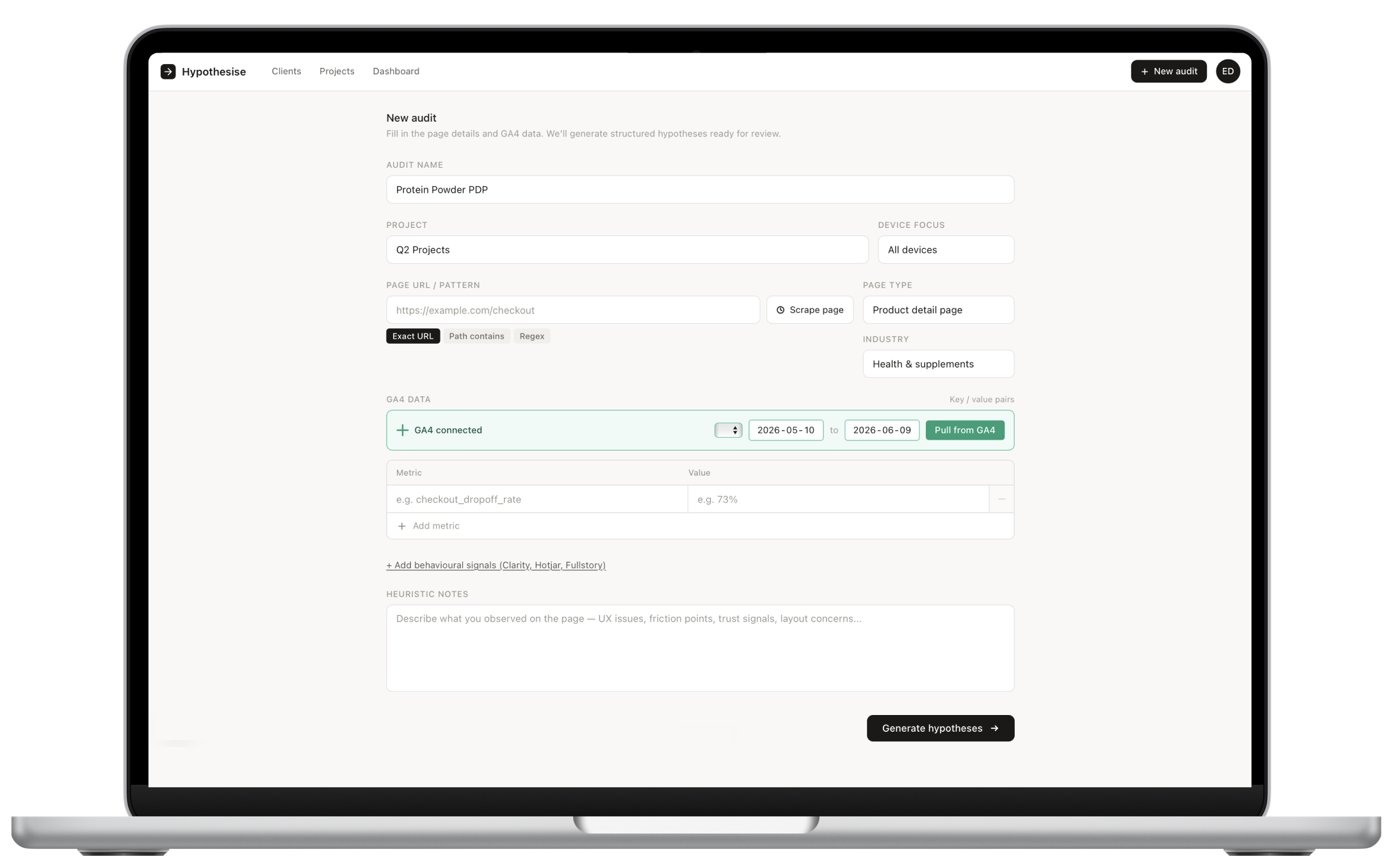
01 — Audit
Create a page audit, pull in metrics, annotate screenshots and session notes.
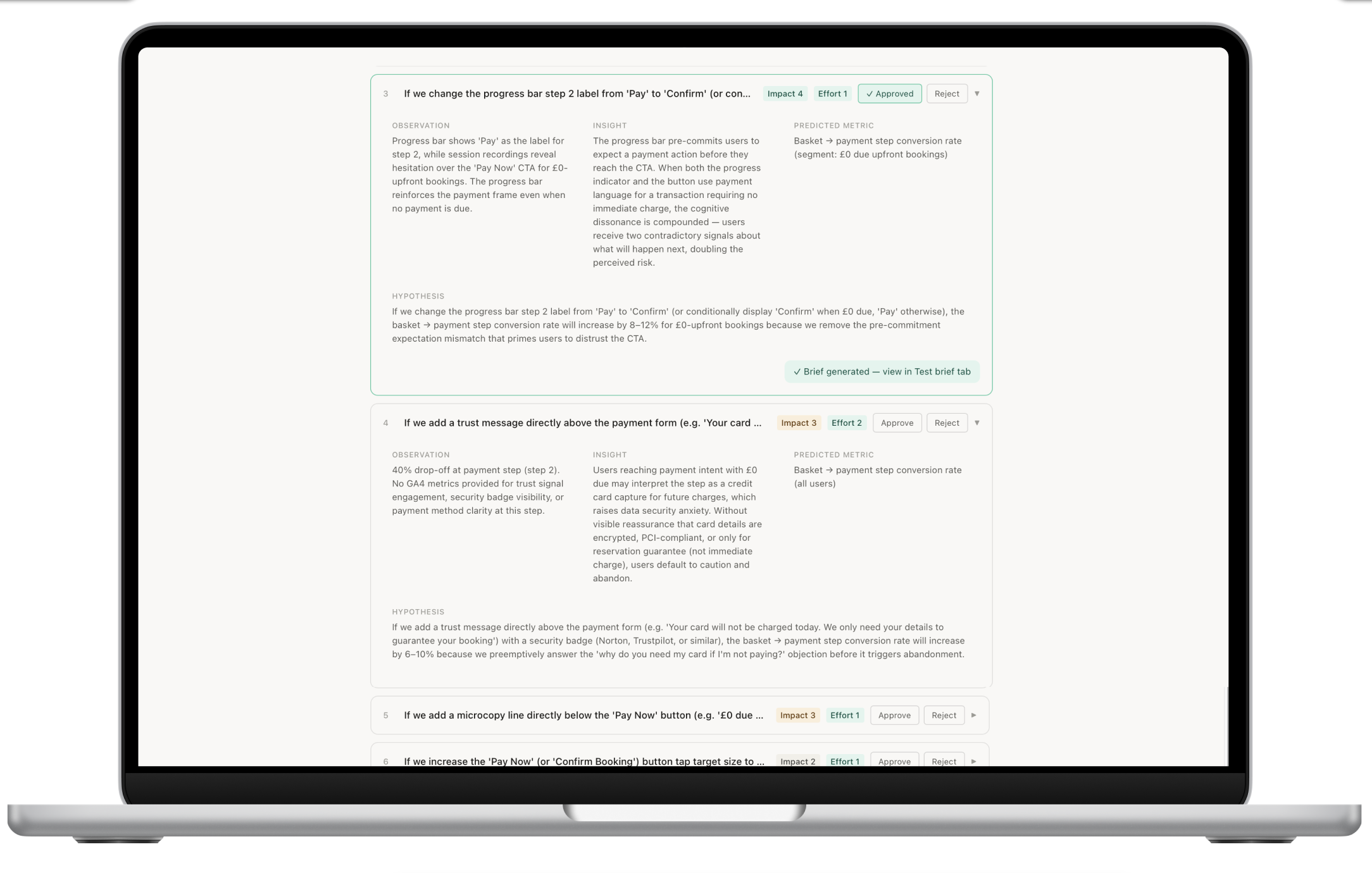
02 — Hypotheses
Claude returns ranked, evidence-backed test ideas from the full picture.
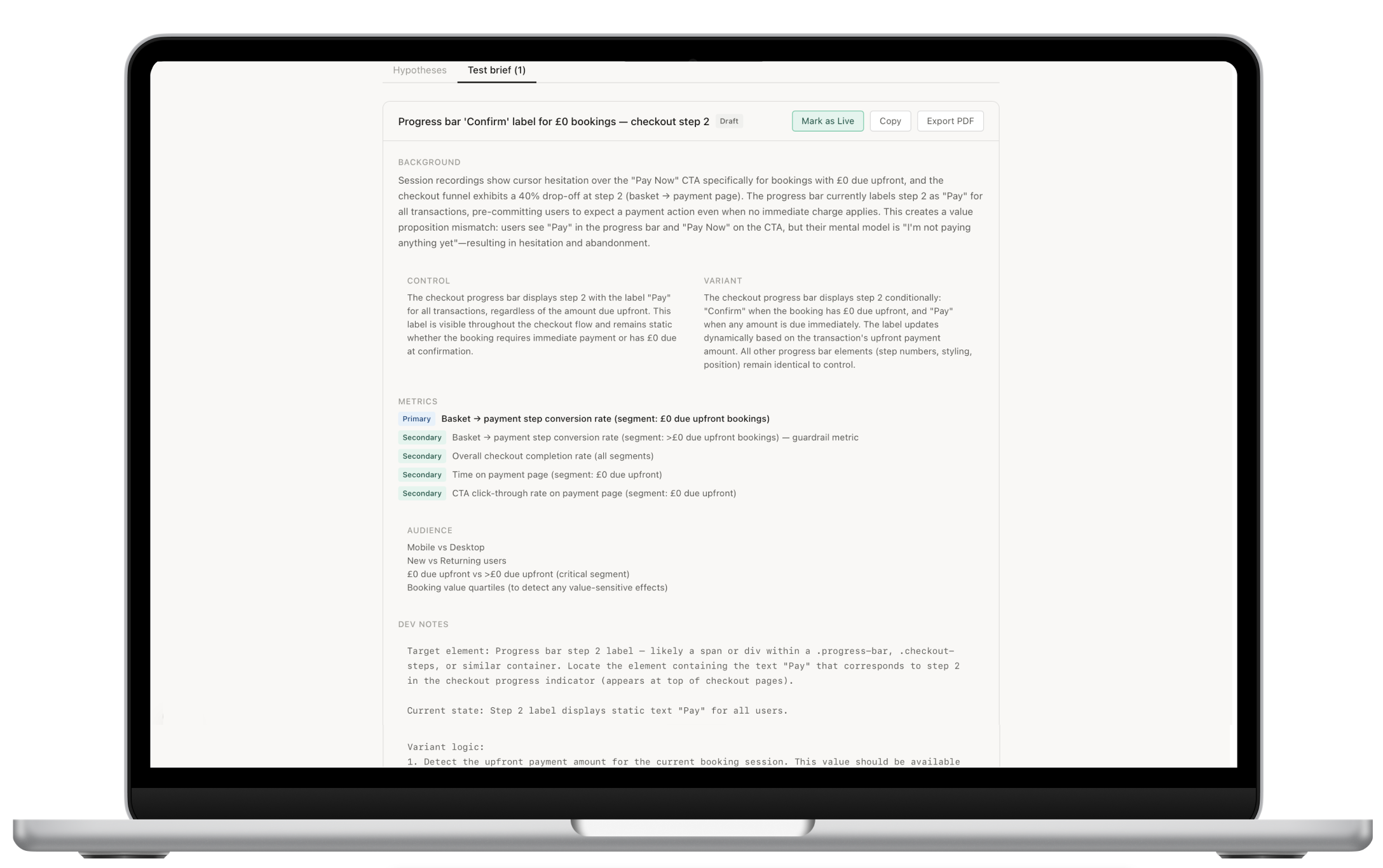
03 — Test Brief
Approve one and get a complete brief — variants, metrics, dev notes, QA checklist.
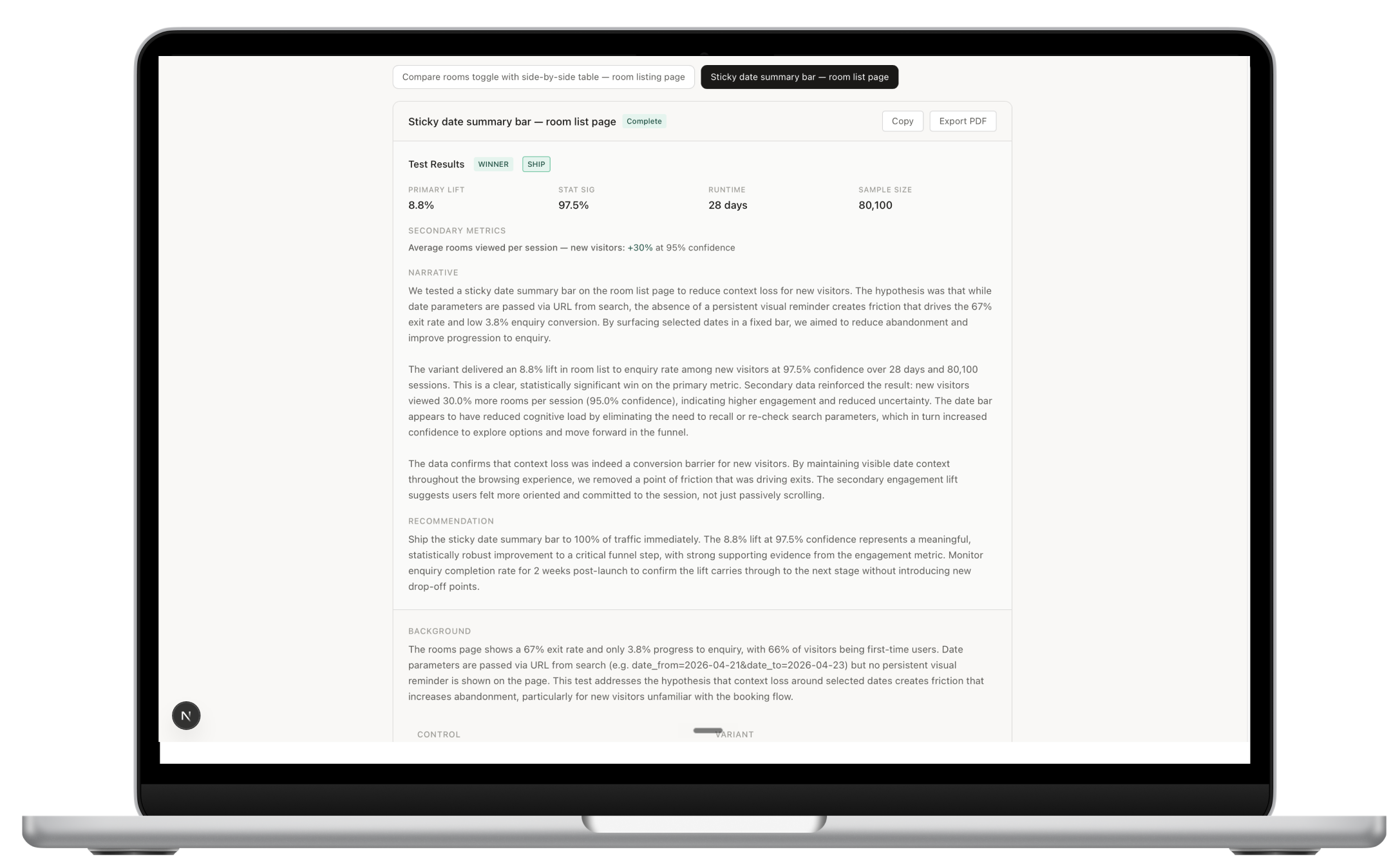
04 — Results
Log outcomes back in. The tool builds institutional memory across every test.
Why I built it
Mostly to see if I could meaningfully improve my own experimentation work — better hypotheses, faster briefs, less time lost between spotting something and acting on it. So far the answer seems to be yes, which is making me think about what a more polished version of this could look like.
Where it's going
Current build covers audit creation, analytics integration, hypothesis generation, brief creation, and results logging. On the roadmap: workspace management and Jira and Linear integration for dev handoff.
The more interesting challenge right now is figuring out how to integrate something I've built for myself into an actual team workflow. That's probably a familiar problem for a lot of firms at the moment — existing processes are rigid, platforms are ingrained, and getting a new tool to sit alongside them without creating duplicative work is harder than it sounds. I'm working through the triggers, webhooks, and automations that would let information flow between systems rather than having to be entered twice. The goal is something that fits into how the team already works, not something that asks everyone to work differently.
The other thing this has made me think about is whether AI just requires work products to look different full stop. The output of a brief, a hypothesis, a handoff doc — the formats we've settled on weren't designed with any of this in mind. I'm going back and forth on whether the answer is format agnosticism or actually stricter, more structured formats that models can reason from reliably. Haven't landed anywhere yet, but it's the thing I'm thinking about most.